
“坊间”流传过分析上市公司公告进行短线买卖股票的炒股战法,本人生性懒惰不能坚持看当日的上市公司公告,大多数情况下都是买入股票(短线)后再去查找相关的资讯。既然学习了python编程,自己搞个每日定时播放上市公司公告的小程序,岂不美哉!
分析“东方财富”、“新浪财经”、“雪球”、“同花顺”等几个财经类门户网站后,从“同花顺”的公告速递栏目中获取上市公司公告数据较好,网站会将公告进行“利好”与”利空“的分类,至于把“利好”当“利好”用,还是当“利空”用,那就是个人对消息面理解的问题了。
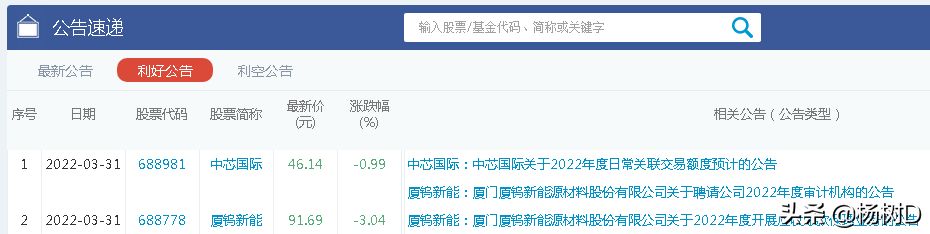
上市公司的公告都是以PDF文档类型发布的,因此我们还得通过一些手段将它转变成文本文件,然后再通过windows的语音接口播放了来,本文主要是用“PDFplumber”模块来实现PDF格式转换的,它可以方便地获取PDF的各种信息,包括文本、表格、图表、尺寸等,但不支持修改或生成PDF。
一、pdfplumber安装
pip install pdfplumber
二、pdfplumber读取pdf
import pdfplumber
import win32com.client
with pdfplumber.open("../b9badee5f9c949b1.pdf") as p: # 打开文档,注意存放的位置
注:怎样获取网站数据参考其它文章
三、生成page对象
page = p.pages[i]
四、对Page对象进行处理
textdata = page.extract_text() # 提取每页的文字信息
五、完整代码
# -*- coding: UTF-8 -*-视频加载中…
import pdfplumber
import win32com.client
with pdfplumber.open("../b9badee5f9c949b1.pdf") as p: # 打开文档,注意存放的位置
page_count = len(p.pages) # 统计文档的页数
for i in range(0, page_count):
page = p.pages[i] # 提取每页的对象并存储
textdata = page.extract_text() # 提取每页的文字信息
data = open('gongao.txt', 'a', encoding='utf-8') # 将文字存放到需要存储的文档里面
data.write(textdata) # 文档写入
data.close()
read_pdf = open("gongao.txt", 'r', encoding='utf-8')
str1 = read_pdf.read()
speak = win32com.client.Dispatch('SAPI.SpVoice')
speak.Speak(str1)
read_pdf.close()
PDF原稿
补充说明:
pdfplumber有两种pdf表格提取函数,分别为.extract_tables( )及.extract_table( ),两种函数提取结果存在差异。对PDF感兴趣的朋友可以试用一下。
1).extract_tables( )
可输出页面中所有表格,并返回一个嵌套列表,其结构层次为table→row→cell。此时,页面上的整个表格被放入一个大列表中,由原表格中的各行组成该大列表中的各个子列表。
2).extract_table( )
返回独立列表,其结构层次为row→cell。若页面中存在多个行数相同的表格,则默认输出顶部表格;否则,仅是输出行数最多的一个表格。此时,表格的每一行都作为一个单独的列表,列表中每个元素即为原表格的各个单元格内容。
 支付宝扫一扫
支付宝扫一扫 微信扫一扫
微信扫一扫






