在上一篇文章中,我们介绍了KNN算法的原理,并详细阐述了使用Opencv的KNN算法模块对手写数字图像进行识别,发现识别的准确率还是比较高的,达到90%以上,这是因为手写数字图像的特征比较简单的缘故。本文我们将使用KNN来对更加复杂的CIFAR-10数据集进行识别分类,并尝试提高分类的准确率。
1. CIFAR-10数据集介绍
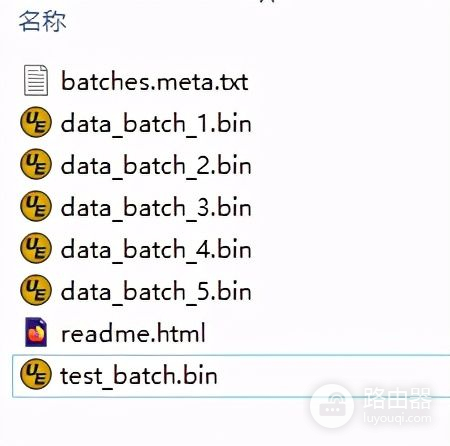
CIFAR-10是一个专门用于测试图像分类的公开数据集,其包含的彩色图像分为10种类型:飞机、轿车、鸟、猫、鹿、狗、蛙、马、船、货车。且这10种类型图像的标签依次为0、1、2、3、4、5、6、7、8、9。该数据集分为Python、Matlab、C/C++三个不同的版本,顾名思义,三个版本分别适用于对应的三种编程语言。因为我们使用的是C/C++语言,所以使用对应的C/C++版本就好,该版本的数据集包含6个bin文件,如下图所示,其中data_batch_1.bin~data_batch_5.bin通常用于训练,而test_batch.bin则用于训练之后的识别测试。
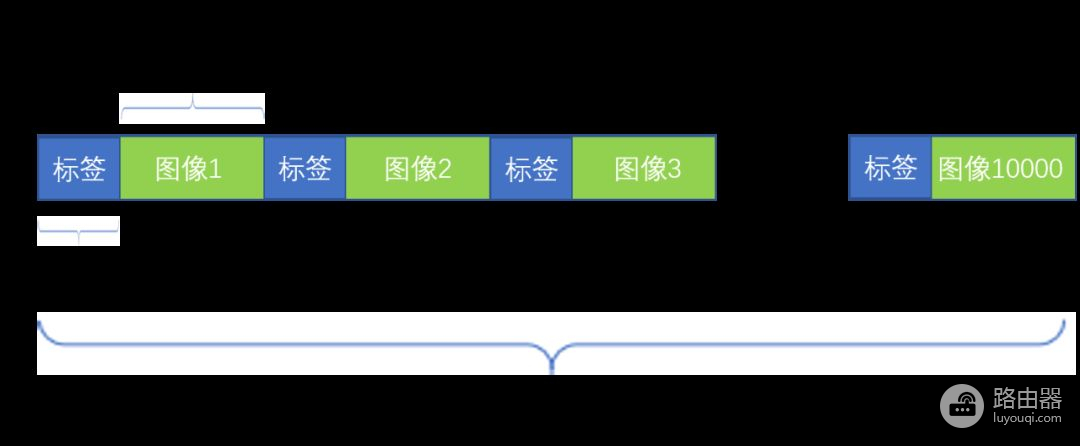
如下图所示,每个bin文件包含10000*3073个字节数据,在每个3073数据块中,第一个字节是0~9的标签,后面3072字节则是彩色图像的三通道数据:红通道 –> 绿通道 –> 蓝通道 (1024 –> 1024 –> 1024)。其中每1024字节的数据就是一帧单通道的32*32图像,3帧32*32字节的单通道图像则组成了一帧彩色图像。所以总体来说,每一个bin文件包含了10000帧32*32的彩色图像。
我们编程把每一个bin文件中包含的图像解析出来,并保存成图像文件。比如对于data_batch_1.bin文件,新建文件夹batch1,然后在batch1文件夹下面再新建名为0~9的10个文件夹,分别保存标签为0~9的图像。
上解析代码:
void read_cifar_bin(char *bin_path, char *save_path){ const int img_num = 10000; const int img_size = 3073; //第一字节是标签 const int img_size_1 = 1024; const int data_size = img_num*img_size; const int row = 32; const int col = 32; uchar *cifar_data = (uchar *)malloc(data_size); if (cifar_data == NULL) { cout << "malloc failed" << endl; return; } FILE *fp = fopen(bin_path, "rb"); if (fp == NULL) { cout << "fopen file failed" << endl; free(cifar_data); return; } fread(cifar_data, 1, data_size, fp); int cnt[10] = {0}; for (int i = 0; i < img_num; i++) { cout << i << endl; long int offset = i*img_size; long int offset0 = offset + 1; //红 long int offset1 = offset0 + img_size_1; //绿 long int offset2 = offset1 + img_size_1; //蓝 uchar label = cifar_data[offset]; //标签 Mat img(row, col, CV_8UC3); for (int y = 0; y < row; y++) { for (int x = 0; x < col; x++) { int idx = y*col + x; img.at(y, x) = Vec3b(cifar_data[offset2+idx], cifar_data[offset1+idx], cifar_data[offset0+idx]); //BGR } } char str[100] = {0}; sprintf(str, "%s/%d/%d.tif", save_path, label, cnt[label]); imwrite(str, img); cnt[label]++; } fclose(fp); free(cifar_data);}
运行上述代码分别解析数据集的6个bin文件,得到6*10000张图像,这时我们有6个文件夹(对应6个bin文件):
以上每个文件夹下又包含了0~9的子文件夹,分别保存对应标签的图像:
2. CIFAR-10数据集的训练与识别
把图像从bin文件解析出来之后,就可以进行训练和识别了,代码与上篇文章类似:
void KNN_cifar_test(void){ char ad[128] = { 0 }; int testnum = 0, truenum = 0; const int K = 8; cv::Ptr knn = cv::ml::KNearest::create(); knn->setDefaultK(K); //设置K值为8 knn->setIsClassifier(true); //设置KNN算法的功能为分类 knn->setAlgorithmType(cv::ml::KNearest::BRUTE_FORCE); //设置KNN算法的模式为遍历所有训练样本,以寻找最接近待分类样本的训练样本 Mat traindata, trainlabel; const int trainnum = 900; //每个batch中的每一个类型的图像都加载900张 //加载batch1训练数据 for (int i = 0; i < 10; i++) { for (int j = 0; j < trainnum; j++) { printf("i=%d, j=%d\n", i, j); sprintf_s(ad, "cifar/batch1/%d/%d.tif", i, j); Mat srcimage = imread(ad, CV_LOAD_IMAGE_GRAYSCALE); //读取灰度图像 srcimage = srcimage.reshape(1, 1); //将二维数据转成一维数据,Mat::reshape(int cn, int rows = 0),cn表示通道数,为0则通道不变,rows表示矩阵行数 traindata.push_back(srcimage); trainlabel.push_back(i); } } //加载batch2训练数据 for (int i = 0; i < 10; i++) { for (int j = 0; j < trainnum; j++) { printf("i=%d, j=%d\n", i, j); sprintf_s(ad, "cifar/batch2/%d/%d.tif", i, j); Mat srcimage = imread(ad, CV_LOAD_IMAGE_GRAYSCALE); srcimage = srcimage.reshape(1, 1); //将二维数据转成一维数据,Mat::reshape(int cn, int rows = 0),cn表示通道数,为0则通道不变,rows表示矩阵行数 traindata.push_back(srcimage); trainlabel.push_back(i); } } //加载batch3训练数据 for (int i = 0; i < 10; i++) { for (int j = 0; j < trainnum; j++) { printf("i=%d, j=%d\n", i, j); sprintf_s(ad, "cifar/batch3/%d/%d.tif", i, j); Mat srcimage = imread(ad, CV_LOAD_IMAGE_GRAYSCALE); srcimage = srcimage.reshape(1, 1); //将二维数据转成一维数据,Mat::reshape(int cn, int rows = 0),cn表示通道数,为0则通道不变,rows表示矩阵行数 traindata.push_back(srcimage); trainlabel.push_back(i); } } //加载batch4训练数据 for (int i = 0; i < 10; i++) { for (int j = 0; j < trainnum; j++) { printf("i=%d, j=%d\n", i, j); sprintf_s(ad, "cifar/batch4/%d/%d.tif", i, j); Mat srcimage = imread(ad, CV_LOAD_IMAGE_GRAYSCALE); srcimage = srcimage.reshape(1, 1); //将二维数据转成一维数据,Mat::reshape(int cn, int rows = 0),cn表示通道数,为0则通道不变,rows表示矩阵行数 traindata.push_back(srcimage); trainlabel.push_back(i); } } //加载batch5训练数据 for (int i = 0; i < 10; i++) { for (int j = 0; j < trainnum; j++) { printf("i=%d, j=%d\n", i, j); sprintf_s(ad, "cifar/batch5/%d/%d.tif", i, j); Mat srcimage = imread(ad, CV_LOAD_IMAGE_GRAYSCALE); srcimage = srcimage.reshape(1, 1); //将二维数据转成一维数据,Mat::reshape(int cn, int rows = 0),cn表示通道数,为0则通道不变,rows表示矩阵行数 traindata.push_back(srcimage); trainlabel.push_back(i); } } traindata.convertTo(traindata, CV_32F); //将训练数据转换为浮点数 knn->train(traindata, cv::ml::ROW_SAMPLE, trainlabel); //进行训练 //加载test测试数据 for (int i = 0; i < 10; i++) { for (int j = 0; j < 800; j++) { testnum++; sprintf_s(ad, "cifar/test_batch/%d/%d.tif", i, j); Mat testdata = imread(ad, CV_LOAD_IMAGE_GRAYSCALE); testdata = testdata.reshape(1, 1); //将二维数据转成一维数据,Mat::reshape(int cn, int rows = 0),cn表示通道数,为0则通道不变,rows表示矩阵行数 testdata.convertTo(testdata, CV_32F); //将测试数据转换为浮点数 Mat result; int response = knn->findNearest(testdata, K, result); //在训练样本中寻找最接近待分类样本的前K个样本,并返回K个样本中数量最多类型的标签 if (response == i) //如果分类得到的标签与数据本来的标签一致,则分类正确 { truenum++; } } } cout << "测试总数" << testnum << endl; cout << "正确分类数" << truenum << endl; cout << "准确率:" << (float)truenum / testnum * 100 << "%" << endl;}
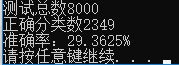
运行上述代码,首先加载训练数据,然后对8000张测试图像进行分类,得到的结果如下。可以看到仅2349张图像识别成功了,29.3625%的识别准确率是非常低的了。
3. 使用HOG特征提高识别准确率
我们识别熟人的时候,主要根据脸部的主要特征来识别的,比如嘴巴、鼻子、眼睛、脸型,或者脸上的痣等,但如果我们根据脸颊的某一小块毫无特点的皮肤来识别,则很可能认错人。同样的道理,计算机的图像识别也是一样的,如果能提取图像的主要特征来进行识别,则可以大大提高识别的准确率。常使用的图像特征有Shift特征、Surf特征、HOG特征等。本文中,我们通过提取图像的HOG特征来进行识别。
首先介绍一下HOG特征。HOG特征算法的核心思想是提取图像的梯度加权直方图。下面分步介绍其提取过程:
(1) 计算图像的梯度图与梯度方向。
图像的梯度分为x方向梯度和y方向梯度,对于图像中任意点(x,y),像素值为I(x,y),其x方向梯度和y方向梯度可分别按下式计算:

得到x方向梯度和y方向梯度之后,即可得到该点的梯度与梯度方向(夹角):
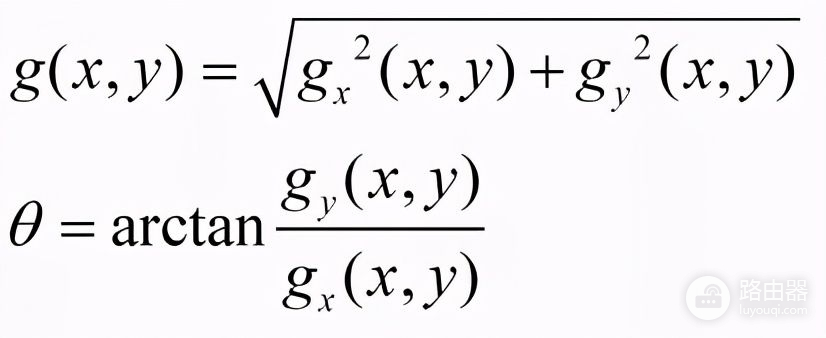
(2) 统计梯度加权直方图。
这里面涉及到三个概念:检测窗口、检测块、检测单元,我们分别介绍一下这三个概念。
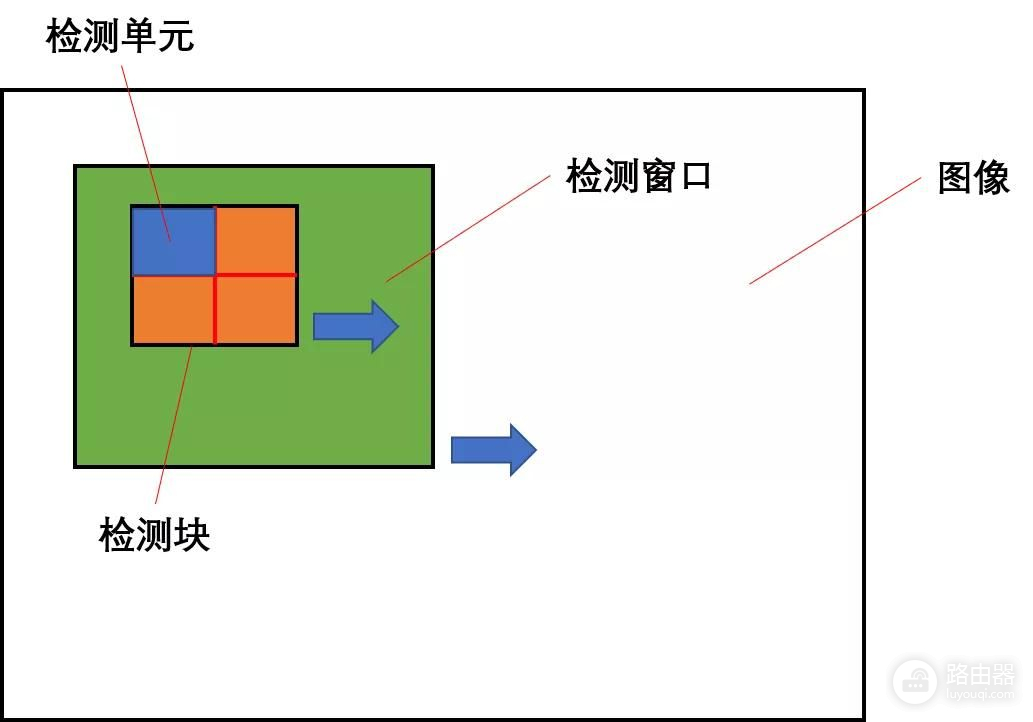
检测窗口:在图像中选择的一个固定大小的矩形窗口,该窗口从左往右、从上往下滑动,每次滑动都有一个固定的步长。
检测块:在检测窗口中选择的一个固定大小的矩形窗口,该窗口从左往右、从上往下滑动,每次滑动都有一个固定的步长。
检测单元:把检测块分成若干个小块,每一个小块就是一个检测单元。比如上图中,把检测快分为2*2的检测单元。
梯度加权直方图的统计,则是以检测单元为单位的,统计每个检测单元中所有点的梯度值与梯度方向。梯度方向的范围为0~359°,通常将其分成9段:0~39、40~79、80~119、120~159、160~199、200~239、240~279、280~319、320~359。根据每一个点的梯度方向,将其划分到对应的段中,同时该段的特征值加上该点的梯度值,比如检测单元中某个点的梯度值为25,梯度方向为67°,则将其划分到40~79段中,同时把40~79段的特征值加上25,这就是加权梯度直方图。
因此,每一个检测单元有9个特征值,检测窗口与检测块滑动过程中的所有检测单元的特征值,就组成了图像的特征值。
Opencv中已经实现了HOG算法。下面我们使用Opencv中的HOG算法模块来检测图像的HOG特征,并对HOG特征进行识别,上代码:
void KNN_cifar_test_hog(void){ char ad[128] = { 0 }; int testnum = 0, truenum = 0; const int K = 8; cv::Ptr knn = cv::ml::KNearest::create(); knn->setDefaultK(K); knn->setIsClassifier(true); knn->setAlgorithmType(cv::ml::KNearest::BRUTE_FORCE); Mat traindata, trainlabel; const int trainnum = 900; //定义HOG检测器 HOGDescriptor *hog = new HOGDescriptor(cvSize(16, 16), cvSize(8, 8), cvSize(8, 8), cvSize(2, 2), 9); //特征提取滑动窗口, 块大小, 块滑动步长, 胞元(cell)大小 vector descriptors; //定义HOG特征数组 //加载训练数据 for (int i = 0; i < 10; i++) { for (int j = 0; j < trainnum; j++) { printf("i=%d, j=%d\n", i, j); sprintf_s(ad, "cifar/batch1/%d/%d.tif", i, j); Mat srcimage = imread(ad, CV_LOAD_IMAGE_GRAYSCALE); //RGB图像的识别比灰度图像的识别率高一点 //计算图像的HOG特征 hog->compute(srcimage, descriptors, Size(4, 4), Size(0, 0)); Mat hogg(descriptors); //将特征数组存入Mat矩阵中 srcimage = hogg.reshape(1, 1); //Mat Mat::reshape(int cn, int rows = 0),cn表示通道数,为0则通道不变,rows表示矩阵行数 traindata.push_back(srcimage); //将HOG特征加载到训练矩阵中 trainlabel.push_back(i); } } for (int i = 0; i < 10; i++) { for (int j = 0; j < trainnum; j++) { printf("i=%d, j=%d\n", i, j); sprintf_s(ad, "cifar/batch2/%d/%d.tif", i, j); Mat srcimage = imread(ad, CV_LOAD_IMAGE_GRAYSCALE); hog->compute(srcimage, descriptors, Size(4, 4), Size(0, 0)); Mat hogg(descriptors); srcimage = hogg.reshape(1, 1); //Mat Mat::reshape(int cn, int rows = 0),cn表示通道数,为0则通道不变,rows表示矩阵行数 traindata.push_back(srcimage); trainlabel.push_back(i); } } for (int i = 0; i < 10; i++) { for (int j = 0; j < trainnum; j++) { printf("i=%d, j=%d\n", i, j); sprintf_s(ad, "cifar/batch3/%d/%d.tif", i, j); Mat srcimage = imread(ad, CV_LOAD_IMAGE_GRAYSCALE); hog->compute(srcimage, descriptors, Size(4, 4), Size(0, 0)); Mat hogg(descriptors); srcimage = hogg.reshape(1, 1); //Mat Mat::reshape(int cn, int rows = 0),cn表示通道数,为0则通道不变,rows表示矩阵行数 traindata.push_back(srcimage); trainlabel.push_back(i); } } for (int i = 0; i < 10; i++) { for (int j = 0; j < trainnum; j++) { printf("i=%d, j=%d\n", i, j); sprintf_s(ad, "cifar/batch4/%d/%d.tif", i, j); Mat srcimage = imread(ad, CV_LOAD_IMAGE_GRAYSCALE); hog->compute(srcimage, descriptors, Size(4, 4), Size(0, 0)); Mat hogg(descriptors); srcimage = hogg.reshape(1, 1); //Mat Mat::reshape(int cn, int rows = 0),cn表示通道数,为0则通道不变,rows表示矩阵行数 traindata.push_back(srcimage); trainlabel.push_back(i); } } for (int i = 0; i < 10; i++) { for (int j = 0; j < trainnum; j++) { printf("i=%d, j=%d\n", i, j); sprintf_s(ad, "cifar/batch5/%d/%d.tif", i, j); Mat srcimage = imread(ad, CV_LOAD_IMAGE_GRAYSCALE); hog->compute(srcimage, descriptors, Size(4, 4), Size(0, 0)); Mat hogg(descriptors); srcimage = hogg.reshape(1, 1); //Mat Mat::reshape(int cn, int rows = 0),cn表示通道数,为0则通道不变,rows表示矩阵行数 traindata.push_back(srcimage); trainlabel.push_back(i); } } traindata.convertTo(traindata, CV_32F); knn->train(traindata, cv::ml::ROW_SAMPLE, trainlabel); for (int i = 0; i < 10; i++) { for (int j = 0; j < 800; j++) { testnum++; sprintf_s(ad, "cifar/test_batch/%d/%d.tif", i, j); Mat testdata = imread(ad, CV_LOAD_IMAGE_GRAYSCALE); hog->compute(testdata, descriptors, Size(4, 4), Size(0, 0)); Mat hogg(descriptors); testdata = hogg.reshape(1, 1); testdata.convertTo(testdata, CV_32F); Mat result; int response = knn->findNearest(testdata, K, result); //识别HOG特征 if (response == i) { truenum++; } } } cout << "测试总数" << testnum << endl; cout << "正确分类数" << truenum << endl; cout << "准确率:" << (float)truenum / testnum * 100 << "%" << endl;}
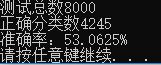
运行上述代码,得到结果如下。可以看到,识别的准确率从之前的29.3625%提升到了53.0625%,提升幅度还是很可观的,不过准确率还是达不到理想的水平,这是KNN算法本身的局限导致的,KNN算法对复杂图像的识别并不擅长,因此在接下来的文章中我们将尝试一下别的图像识别算法。
 支付宝扫一扫
支付宝扫一扫 微信扫一扫
微信扫一扫


