
背景
传统Web应用中所有的功能部署在一起,图片、文件也在一台服务器;应用微服务架构后,服务之间的图片共享通过FTP+Nginx静态资源的方式进行访问,文件共享通过nfs磁盘挂载的方式进行访问,无论是单体架构还是微服务架构下的应用都存在大量图片、文件读写操作,但是昂贵的磁盘空间、高性能服务器无疑增加了运营成本。
所以我们希望文件服务也能微服务、独立化,这样既能降低运营成本,又能对文件进行统一的管理和维护,所以搭建独立的文件服务是解决文件共享、释放业务系统压力的最优选择。于是便诞生了随行付分布式文件系统简称OSS(Object Storage Service),提供的海量、安全、低成本、高可靠的云存储服务。它具有与平台无关的RESTful API接口,能够提供数据可靠性和服务可用性。
文件服务的意义
随着互联网图片、视频时代的到来,对文件的处理成为各个业务系统面临的巨大挑战,没有文件服务器之前,系统之间处理图片的方式大相径庭:FTP、NFS、数据库存储等等,虽然都实现了对文件的存储、访问,但是系统之间很难达到文件共享,所以文件服务可以形成一个统一的访问标准,降低各个系统之间的互相依赖,提高开发效率、释放业务系统压力,所以文件服务的意义如下:
降低WEB服务器压力
分担业务服务器的I0、流程负载,将耗费资源的文件访问、读写操作分离到文件服务器,可以提高服务器的性能和稳定性,降低WEB服务器成本。
独立服务易扩展
文件服务像微服务架构独立化,可以有针对性的进行配置提高性能;独立域名让图片管理、CDN缓存文件更方便,随时扩展文件服务器数量,即不影响业务又能增加文件服务器并发访问。
统一访问格式
开发者无需关心存储路径、存储介质、文件备份等,丰富的API帮助系统快速存储、共享文件,提高项目开发速度。
安全认证
文件服务对资源访问可以增加认证、权限等安全措施,防止服务器资源被盗用,有效的隔离了数据访问。
文件服务基本概念
为便于更好的理解对象存储OSS,需要了解对象存储中的几个概念。
对象/文件(Object)
对象是OSS存储数据的基本单元,也被称为OSS的文件。对象由元信息(Object Meta),用户数据(Data)和文件名(Key)组成。对象由存储空间内部唯一的Key来标识。对象元信息是一个键值对,表示了对象的一些属性,比如最后修改时间、大小等信息,同时用户也可以在元信息中存储一些自定义的信息。对象的生命周期是从上传成功到被删除为止。在整个生命周期内,对象信息不可变更。重复上传同名的对象会覆盖之前的对象,因此,OSS 不支持修改文件的部分内容等操作。
存储空间(Bucket)
存储空间是用于存储对象(Object)的容器,所有的对象都必须隶属于某个存储空间。可以设置和修改存储空间属性用来控制地域、访问权限、生命周期等,这些属性设置直接作用于该存储空间内所有对象,因此可以通过灵活创建不同的存储空间来完成不同的管理功能。
同一个存储空间的内部是扁平的,没有文件系统的目录等概念,所有的对象都直接隶属于其对应的存储空间。
每个用户可以拥有多个存储空间。
存储空间的名称在 OSS 范围内必须是全局唯一的,一旦创建之后无法修改名称。
存储空间内部的对象数目没有限制。
访问密钥(AppKey & AppSecret)
AppKey代表应用身份,AppSecret即应用密钥,用于生成签名认证,请求文件服务时必须要传递appkey和签名生产的token,网关根据请求验证请求的合法性性和时效性。
文件服务的功能
应用场景 功能描述
上传文件 创建存储空间后,您可以上传任意文件到该存储空间
搜索文件 可以在存储空间中搜索文件或文件夹
查看或下载文件 通过文件 URL 查看或者下载文件
删除文件或文件夹 删除单个或者多个文件/文件夹,还可以删除分片上传产生的碎片,节省存储空间
访问权限 可以通过应用授权和桶授权的方式,授予存储空间和对象访问权限的访问策略
访问信息 自动记录对OSS资源的详细访问信息
防盗链 防止OSS上的数据被其他人盗用,设置防盗链
监控服务 预警OSS服务使用情况的实时信息,如基本的系统运行状态和性能
API和SDK OSS 提供 RESTful API和各种语言的SDK开发包方便您快速进行二次开发
架构设计
OSS以分布式文件系统ceph作为底层存储,支持SDK或者浏览器以http的形式上传和下载文件,网关负责路由访问请求到文件服务集群ossWork,ossWork生成文件唯一保存路径后存储文件到ceph,并返回加密后访问地址给用户。 架构图如下:
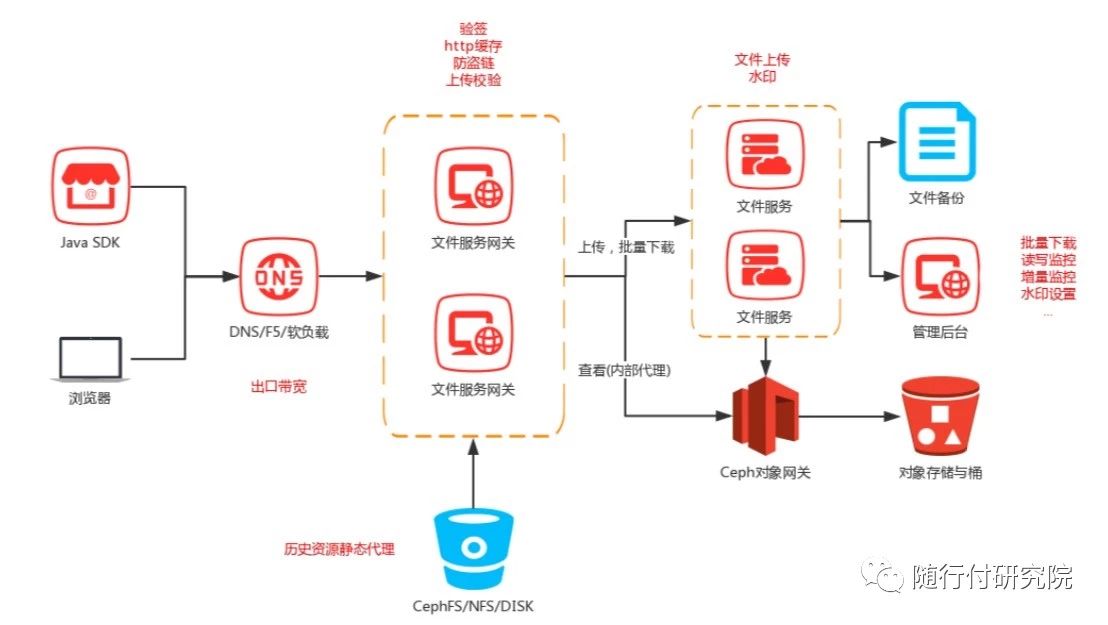
原理介绍:
1.OSS采用OpenResty作为网关处理请求转发和校验,OpenResty汇聚了nginx的核心功能模块,还支持lua脚本方便对nginx功能的扩展,而且nginx多路复用机制和非阻塞的IO非常适合耗时短、业务简单的校验操作:权限验证、防盗链、黑白名单等,不仅如此nginx还能作为网关的缓存,这些特性极大提升了网关性能和并发访问。
2.ossWork作为文件服务,处理图片水印、缩放、url加密、解密等,还封装与底层存储的交互。
3.ossKeeper作为文件管理后台,负责权限接入注册、申请、监控报表展示。
4.ossMonitor日志收集、计算汇总、数据存储。
5.ossBackup负责文件异步备份。
oss子系统相关流程图如下:
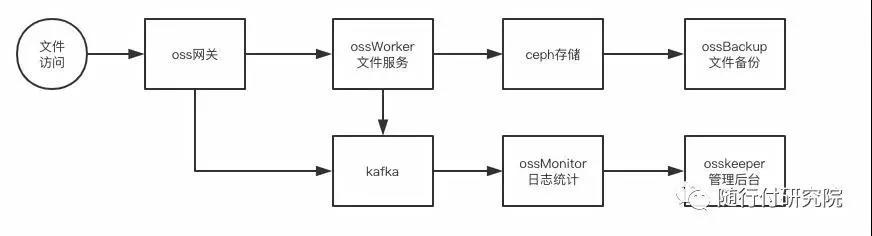
核心实现
OSS主要为随行付各个业务系统提供文件共享和访问服务,并且可以按应用统计流量、命中率、空间等指标。下面将介绍OSS核心功能以及实现。主要包括:缓存、用户认证、权限管理、url加密解密、监控统计等。
缓存
提升性能的关键是缓存,OSS采用二级缓存:浏览器缓存、网关层缓存提升响应速度,具体如下:

第一次请求文件时,OSS返回文件给浏览器http的状态码是200
第二次请求时同一个文件时,服务器根据请求中HTTP协议中的max-age/Expires,判断文件未修改,返回状态码403,告诉浏览器可以继续使用本地缓存
第三次请求F5强制刷新,网关根据If-Modified-Since、Cache-Control:no-cache和Pragma:no-cache等信息重新返回nginx中缓存文件
第四次请求url时,requesturi不一样但文件是同一个,nginx根据requesturi判断网关中无此文件,请求底层存储返回文件。
用户认证
为避免文件、图片盗用,浪费服务器流量和IO等资源,OSS采用防盗链的方式认证请求。每个使用OSS服务的系统都需要进行注册、申请应用,成功后自动生成appkey、appsecret。appkey代表应用身份,appsecret即应用密钥,用于生成签名认证,请求文件服务时必须要传递appkey和签名生产的token,网关根据请求验证请求的合法性性和时效性。后台管理appkey的生成及防盗链的签名如下图:


手机终端认证
手机端认证同server端一样,但是由于账户信息的安全问题,appkey和appsecret只能保存在服务端,手机终端访问oss时无法生成签名,那么手机端如何访问oss服务?这里我们采用oauth认证的原理:

app用户登录终端系统,App发送请求OSS request请求
server收到请求后,向OSS申请资源的临时授权token
OSS接收授权请求后,生成临时访问token返回给server
server组装文件地址与临时的token,返回给app
权限管理
每个应用有了自己的appkey,文件访问时通过appkey验证身份,默认文件的归属只有上传者可以查看或修改,上传者可以授权给其他账户,通过在后台管理-权限配置功能授权授权的级别分为:修改、查看、删除,不同的级别对应不同的操作,后台管理系统会实时同步文件权限到文件系统。这样其他账户只需要传递自身的appkey就可以对此文件访问。具体流程及具体配置如下:


URL加解密、规范(实现参考)
底层存储中的文件名称必须全局唯一,oss采用自定义算法生成文件名称,命名规范=时间戳+分隔符+线程ID+分隔符+进程ID+分隔符+客户端IP,URL规范图解如下:

为了保证oss服务器的安全,防止程序文件和目录外泄,oss对url进行了私有协议的加密,按分隔符“_”对每一项进行base64编码,再按62位字典码加密生成加后的url,当然也有其他的算法实现,是要实现url加密即可。解密是对加密的逆向操作,解密后的url即为储存的访问url。服务端的规范样例及客户端的url规范样例:


oss统计监控
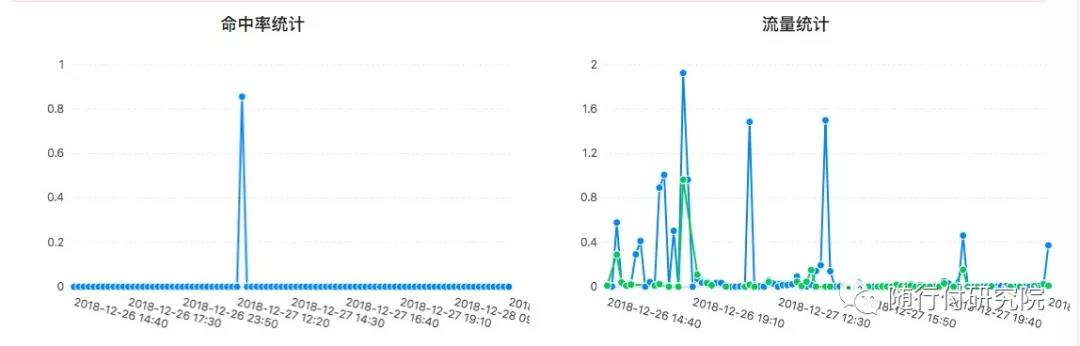
为保证文件服务的质量和可靠性,系统的监控和告警是必不可少的,各个阶段的运行信息,以日志的形式写到文件中,再使用Flume日志收集组件采集各个子系统的日志,按日志类别直接发送到kafka的不同topic,ossMonitor读取kafka中消息,以时间为单位计算流量、命中率,以空间为单位统计使用率,根据上传日志是否有异常发送告警邮件,流程如下:

Flume是由cloudera软件公司产出的可分布式日志收集系统,由source,channel,sink三个组件组成:
Source:
从数据发生器接收数据,并将接收的数据以Flume的event格式传递给一个或者多个通道channal,Flume提供多种数据接收的方式,比如Avro,Thrift,txt等
Channel:
channal是一种短暂的存储容器,它将从source处接收到的event格式的数据缓存起来,直到它们被sinks消费掉,它在source和sink间起着一共桥梁的作用,channal是一个完整的事务,这一点保证了数据在收发的时候的一致性. 并且它可以和任意数量的source和sink链接. 支持的类型有: JDBC channel , File System channel , Memort channel等.
Sink:
sink将数据存储到集中存储器比如Hbase和kafka,它从channals消费数据(events)并将其传递给目标地.
Flume配置如下:
gateway.sources = fileEvent
gateway.channels = kafkaChannel
gateway.sinks = loggerSink
For each one of the sources, the type is defined
gateway.sources.fileEvent.type = TAILDIR
gateway.sources.fileEvent.positionFile = / xxx.json
gateway.sources.fileEvent.filegroups = events
gateway.sources.fileEvent.filegroups.events=/xxx.log
gateway.sources.fileEvent.type = spooldir
The channel can be defined as follows.
gateway.sources.fileEvent.channels = kafkaChannel
gateway.sources.fileEvent.channels = kafkaChannel
gateway.sources.fileEvent.spoolDir = /home/app/oss_events
Each sink’s type must be defined
gateway.sinks.loggerSink.type = org.apache.flume.sink.kafka.KafkaSink
Specify the channel the sink should use
gateway.sinks.loggerSink.channel = kafkaChannel
gateway.sinks.loggerSink.kafka.bootstrap.servers=xxx.xxx.xxx.xxx:9092
gateway.sinks.loggerSink.kafka.topic=oss-gateway-events
gateway.sinks.loggerSink.kafka.batchSize=20
gateway.sinks.loggerSink.kafka.producer.requiredAcks=1
Each channel’s type is defined.
gateway.channels.kafkaChannel.type = memory
Other config values specific to each type of channel(sink or source)
can be defined as well
In this case, it specifies the capacity of the memory channel
gateway.channels.kafkaChannel.capacity = 30000
gateway.channels.kafkaChannel.transactionCapacity = 100
统计图如下:
 支付宝扫一扫
支付宝扫一扫 微信扫一扫
微信扫一扫








