
参考:

=======================================================
在pytorch中有几个关于显存的关键词:
在pytorch中显存为缓存和变量分配的空间之和叫做reserved_memory,为变量分配的显存叫做memory_allocated,由此可知reserved_memory一定大于等于memory_allocated,但是pytorch获得总显存要比reserved_memory要大,pytorch获得的总显存空间为reserved_memory+PyTorch context。
在不同显卡和驱动下PyTorch context的大小是不同的,如:
https://zhuanlan.zhihu.com/p/424512257
所述,RTX 3090的context 开销。其中3090用的CUDA 11.3,开销为1639MB。
执行代码:
import torch temp = torch.tensor([1.0]).cuda()
NVIDIA显存消耗:

其中:

我们知道memory_reserved大小为2MB,那么context大小大约为1639MB。
给出
https://zhuanlan.zhihu.com/p/424512257
图片:

可以知道,pytorch并没有直接采用操作系统的显存管理机制而是自己又写了一个显存管理机制,使用这种层级的管理机制在cache中申请显存不需要向OS申请而是在自己的显存管理程序中进行调配,如果自己的cache中显存空间不够再会通过OS来申请显存,通过这种方法可以进一步提升显存的申请速度和减少显存碎片,当然这样也有不好的地方,那就是多人使用共享显卡的话容易导致一方一直不释放显存而另一方无法获得足够显存,当然pytorch也给出了一些显存分配的配置方法,但是主要还是为了减少显存碎片的。
对 https://zhuanlan.zhihu.com/p/424512257 中代码进行一定修改:
import torch s = 0 # 模型初始化 linear1 = torch.nn.Linear(1024,1024, bias=False).cuda() # + 4194304 s = s+4194304 print(torch.cuda.memory_allocated(), s) linear2 = torch.nn.Linear(1024, 1, bias=False).cuda() # + 4096 s+=4096 print(torch.cuda.memory_allocated(), s) # 输入定义 inputs = torch.tensor([[1.0]*1024]*1024).cuda() # shape = (1024,1024) # + 4194304 s+=4194304 print(torch.cuda.memory_allocated(), s) # 前向传播 s=s+4194304+512 loss = sum(linear2(linear1(inputs))) # shape = (1) # memory + 4194304 + 512 print(torch.cuda.memory_allocated(), s) # 后向传播 loss.backward() # memory - 4194304 + 4194304 + 4096 s = s-4194304+4194304+4096 print(torch.cuda.memory_allocated(), s) # 再来一次~ loss = sum(linear2(linear1(inputs))) # shape = (1) # memory + 4194304 (512没了,因为loss的ref还在) s+=4194304 print(torch.cuda.memory_allocated(), s) loss.backward() # memory - 4194304 s-=4194304 print(torch.cuda.memory_allocated(), s)

============================================


=================================================
修改代码:


import torch s = 0 # 模型初始化 linear1 = torch.nn.Linear(1024,1024, bias=False).cuda() # + 4194304 s = s+4194304 print(torch.cuda.memory_allocated(), s) linear2 = torch.nn.Linear(1024, 1, bias=False).cuda() # + 4096 s+=4096 print(torch.cuda.memory_allocated(), s) # 输入定义 inputs = torch.tensor([[1.0]*1024]*1024).cuda() # shape = (1024,1024) # + 4194304 s+=4194304 print(torch.cuda.memory_allocated(), s) # 前向传播 s=s+4194304+512 loss = sum(linear2(linear1(inputs))) # shape = (1) # memory + 4194304 + 512 print(torch.cuda.memory_allocated(), s) # 后向传播 loss.backward() # memory - 4194304 + 4194304 + 4096 s = s-4194304+4194304+4096 print(torch.cuda.memory_allocated(), s) # 再来一次~ for _ in range(10000): loss = sum(linear2(linear1(inputs))) # shape = (1) # memory + 4194304 (512没了,因为loss的ref还在) loss.backward() # memory - 4194304 print(torch.cuda.max_memory_reserved()/1024/1024, "MB") print(torch.cuda.max_memory_allocated()/1024/1024, "MB") print(torch.cuda.max_memory_cached()/1024/1024, "MB") print(torch.cuda.memory_summary())
View Code


那么问题来了,问了保证这个程序完整运行下来的显存量是多少呢???
已经知道最大的reserved_memory 为 22MB,那么保证该程序运行的最大显存空间为reserved_memory+context_memory,
这里我们是使用1060G显卡运行,先对一下context_memory:
执行代码:
import torch
temp = torch.tensor([1.0]).cuda()
NVIDIA显存消耗:
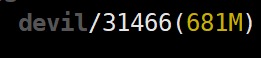
所以context_memory为681MB-2MB=679MB
由于max_reserved_memory=22MB,因此该程序完整运行下来最高需要679+22=701MB,验证一下:
再次运行代码:
import torch import time s = 0 # 模型初始化 linear1 = torch.nn.Linear(1024,1024, bias=False).cuda() # + 4194304 s = s+4194304 print(torch.cuda.memory_allocated(), s) linear2 = torch.nn.Linear(1024, 1, bias=False).cuda() # + 4096 s+=4096 print(torch.cuda.memory_allocated(), s) # 输入定义 inputs = torch.tensor([[1.0]*1024]*1024).cuda() # shape = (1024,1024) # + 4194304 s+=4194304 print(torch.cuda.memory_allocated(), s) # 前向传播 s=s+4194304+512 loss = sum(linear2(linear1(inputs))) # shape = (1) # memory + 4194304 + 512 print(torch.cuda.memory_allocated(), s) # 后向传播 loss.backward() # memory - 4194304 + 4194304 + 4096 s = s-4194304+4194304+4096 print(torch.cuda.memory_allocated(), s) # 再来一次~ for _ in range(10000): loss = sum(linear2(linear1(inputs))) # shape = (1) # memory + 4194304 (512没了,因为loss的ref还在) loss.backward() # memory - 4194304 print(torch.cuda.max_memory_reserved()/1024/1024, "MB") print(torch.cuda.max_memory_allocated()/1024/1024, "MB") print(torch.cuda.max_memory_cached()/1024/1024, "MB") print(torch.cuda.memory_summary()) time.sleep(60)
View Code

发现 803-701=102MB,这中间差的数值无法解释,只能说memory_context可以随着程序不同数值也不同,不同程序引入的pytorch函数不同导致context_memory也不同,这里我们按照这个想法反推,context_memory在这里为803-22=781MB,为了验证我们修改代码:
修改代码:
import torch import time s = 0 # 模型初始化 linear1 = torch.nn.Linear(1024,1024*2, bias=False).cuda() # + 4194304 s = s+4194304 print(torch.cuda.memory_allocated(), s) linear2 = torch.nn.Linear(1024*2, 1, bias=False).cuda() # + 4096 s+=4096 print(torch.cuda.memory_allocated(), s) # 输入定义 inputs = torch.tensor([[1.0]*1024]*1024).cuda() # shape = (1024,1024) # + 4194304 s+=4194304 print(torch.cuda.memory_allocated(), s) # 前向传播 s=s+4194304+512 loss = sum(linear2(linear1(inputs))) # shape = (1) # memory + 4194304 + 512 print(torch.cuda.memory_allocated(), s) # 后向传播 loss.backward() # memory - 4194304 + 4194304 + 4096 s = s-4194304+4194304+4096 print(torch.cuda.memory_allocated(), s) # 再来一次~ for _ in range(100): loss = sum(linear2(linear1(inputs))) # shape = (1) # memory + 4194304 (512没了,因为loss的ref还在) loss.backward() # memory - 4194304 print(torch.cuda.max_memory_reserved()/1024/1024, "MB") print(torch.cuda.max_memory_allocated()/1024/1024, "MB") print(torch.cuda.max_memory_cached()/1024/1024, "MB") print(torch.cuda.memory_summary()) time.sleep(60)
View Code
运行结果:

那么该代码完整运行需要的显存空间为:781+42=823MB
参考NVIDIA显卡的显存消耗:

发现支持刚才的猜想,也就是说不同的pytorch函数,显卡型号,驱动,操作系统,cuda版本都是会影响context_memory大小的。
其中最为难以测定的就是pytorch函数,因为你可能一直在同一个平台上跑代码但是不太可能一直都用相同的pytorch函数,所以一个程序跑完最低需要的显存空间的测定其实是需要完整跑一次网络的反传才可以测定的。
我这里采用的测定最低需要的显存空间的方法是不考虑context_memory而去直接考虑一次反传后最大需要的显存,此时我们可以一次反传后把程序挂住,如sleep一下,然后看下NVIDIA显卡一共消耗了多少显存。而且由上面的信息可知context_memory的测定是与具体使用的函数相关的,因此最稳妥的方法就是使用NVIDIA-smi监测一次完整反传后最大显存的消耗。
=====================================================
本博客是博主个人学习时的一些记录,不保证是为原创,个别文章加入了转载的源地址还有个别文章是汇总网上多份资料所成,在这之中也必有疏漏未加标注者,如有侵权请与博主联系。
 支付宝扫一扫
支付宝扫一扫 微信扫一扫
微信扫一扫






